
Klasifikasi Dataset dengan Pemodelan Naïve Bayes menggunakan Python
Algoritma Naive Bayes menonjol sebagai pilihan yang sangat baik untuk pemodelan klasifikasi, terutama bagi mereka yang baru memasuki dunia analisis data. Kemudahannya dalam implementasi dan pemahaman membuatnya menjadi opsi yang sesuai untuk pemula dalam pemodelan. Keunggulan lainnya terletak pada efisiensi komputasinya yang tinggi, menghasilkan waktu komputasi yang cepat karena sederhananya dan perhitungan yang efisien. Selain itu, Naive Bayes juga menunjukkan kinerja yang memuaskan bahkan dengan dataset yang besar, menjadikannya pilihan yang andal untuk data yang melibatkan banyak fitur atau variabel. Dengan kombinasi kemudahan implementasi, efisiensi komputasi, dan kinerja yang baik pada data besar, Naive Bayes menjadi alat yang berharga dalam analisis klasifikasi.
Data Overview
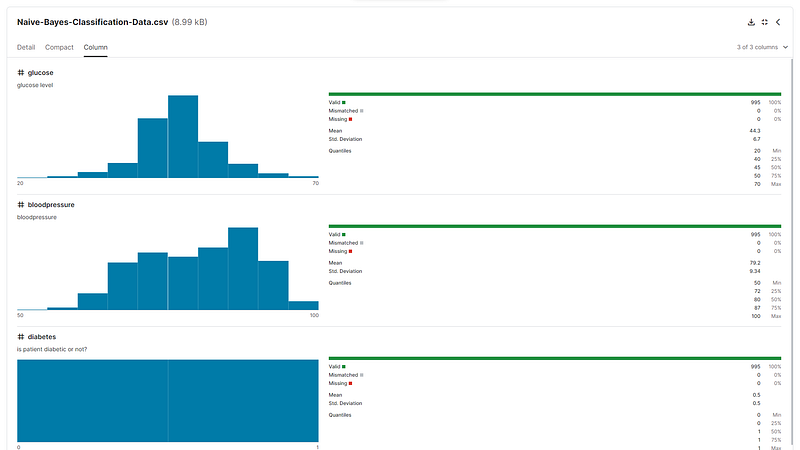
Dalam gambaran data, berikut merupakan contoh dataset yang telah diperoleh untuk analisis. data set dalam gambar tersebut adalah sebuah tabel yang berisi data hasil tes darah untuk glukosa, tekanan darah, dan diabetes. Tabel tersebut terdiri dari 966 baris dan 3 kolom. Kolom pertama berisi glukosa, kolom kedua berisi hasil tekanan darah, dan kolom ketiga berisi hasil diabetes.
Splitting Dataset for Modelling Classification
file_path = "Naive-Bayes-Classification-Data.csv"
data = pd.read_csv(file_path)
imputer = SimpleImputer(strategy="mean")
data = pd.DataFrame(imputer.fit_transform(data), columns=data.columns)
X = data.drop('diabetes', axis=1)
y = data['diabetes']
scaler = StandardScaler()
X = pd.DataFrame(scaler.fit_transform(X), columns=X.columns)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
- Memisahkan Fitur dan Target:
X = data.drop(‘diabetes’, axis=1): Mengambil semua kolom kecuali kolom ‘diabetes’ sebagai fitur yang akan digunakan untuk melatih model.
y = data[‘diabetes’]: Memilih kolom ‘diabetes’ sebagai target atau label dari dataset. - Normalisasi atau Standarisasi Fitur:
scaler = StandardScaler(): Inisialisasi objek scaler untuk melakukan standarisasi atau normalisasi data.X = pd.DataFrame(scaler.fit_transform(X), columns=X.columns): Melakukan normalisasi pada fitur-fitur yang dipisahkan sebelumnya. Proses ini bertujuan untuk membuat fitur-fitur memiliki skala yang serupa untuk memastikan bahwa tidak ada fitur yang mendominasi yang lainnya dalam model. - Pembagian Dataset untuk Pelatihan dan Pengujian:
Proses pemisahan dataset menjadi subset pelatihan dan pengujian merupakan langkah kritis dalam pengembangan model, dan dalam implementasinya, kita menggunakan fungsi train_test_split dari pustaka scikit-learn. Dalam kasus ini, dataset awal (X, y) dibagi menjadi empat bagian utama:X_train, y_train, X_test, dan y_test. Proporsi pembagian ditentukan oleh parameter test_size=0.2, yang mengindikasikan bahwa 20% dari data akan dialokasikan sebagai dataset pengujian, sedangkan 80% sisanya digunakan untuk melatih model. Penggunaan random_state=42 bertujuan untuk menjamin reproduktivitas hasil, memastikan bahwa setiap kali proses pemisahan dilakukan, hasilnya akan konsisten dan dapat direproduksi. Dengan demikian, langkah ini memberikan dasar yang solid untuk melatih dan menguji model secara konsisten dalam pengembangan analisis data.
Machine Learning Implementation & Model Evolution
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt
import seaborn as sns
file_path = "Naive-Bayes-Classification-Data.csv"
data = pd.read_csv(file_path)
/ Handling missing values
imputer = SimpleImputer(strategy="mean")
data = pd.DataFrame(imputer.fit_transform(data), columns=data.columns)
X = data.drop('diabetes', axis=1)
y = data['diabetes']
/ Standardize the features
scaler = StandardScaler()
X = pd.DataFrame(scaler.fit_transform(X), columns=X.columns)
/ Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
/ Create and train the Naive Bayes classifier
naive_bayes_classifier = GaussianNB()
naive_bayes_classifier.fit(X_train, y_train)
/ Make predictions on the test set
y_pred = naive_bayes_classifier.predict(X_test)
/ Evaluate the model
accuracy = accuracy_score(y_test, y_pred)
conf_matrix = confusion_matrix(y_test, y_pred)
classification_rep = classification_report(y_test, y_pred)
/ Print evaluation metrics
print("Accuracy:", accuracy)
print("\nConfusion Matrix:\n", conf_matrix)
print("\nClassification Report:\n", classification_rep)
/ Plot the Confusion Matrix
plt.figure(figsize=(8, 6))
sns.heatmap(conf_matrix, annot=True, fmt="d", cmap="Blues", cbar=False,
xticklabels=["Predicted 0", "Predicted 1"],
yticklabels=["Actual 0", "Actual 1"])
plt.xlabel("Predicted Label")
plt.ylabel("True Label")
plt.title("Confusion Matrix")
plt.show()
Langkah-langkah utama yang diambil mencakup penanganan nilai yang hilang dengan menggantinya menggunakan rata-rata, standardisasi fitur-fitur dataset untuk memastikan distribusi yang seragam, dan pemisahan dataset menjadi subset pelatihan dan pengujian. Setelah itu, model klasifikasi Naive Bayes, khususnya Gaussian Naive Bayes, dibuat dan dilatih menggunakan subset pelatihan. Prediksi kemudian dibuat pada dataset pengujian, dan performa model dievaluasi dengan metrik akurasi, matriks kebingungan (confusion matrix), dan laporan klasifikasi. Terakhir, untuk memberikan pemahaman visual tentang kinerja model, matriks kebingungan dipresentasikan dalam bentuk heatmap. Keseluruhan, tujuan dari kode ini adalah untuk mengembangkan, melatih, dan mengevaluasi model klasifikasi Naive Bayes untuk memprediksi kasus diabetes berdasarkan fitur-fitur yang ada dalam dataset.
Result
Kami berhasil memecahkan masalah studi kasus kami, dengan analisis hasil sebagai berikut:
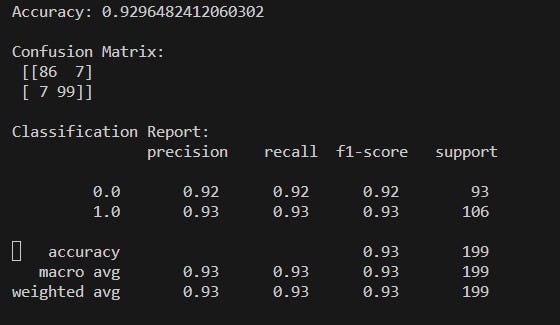
- Akurasi (Accuracy):
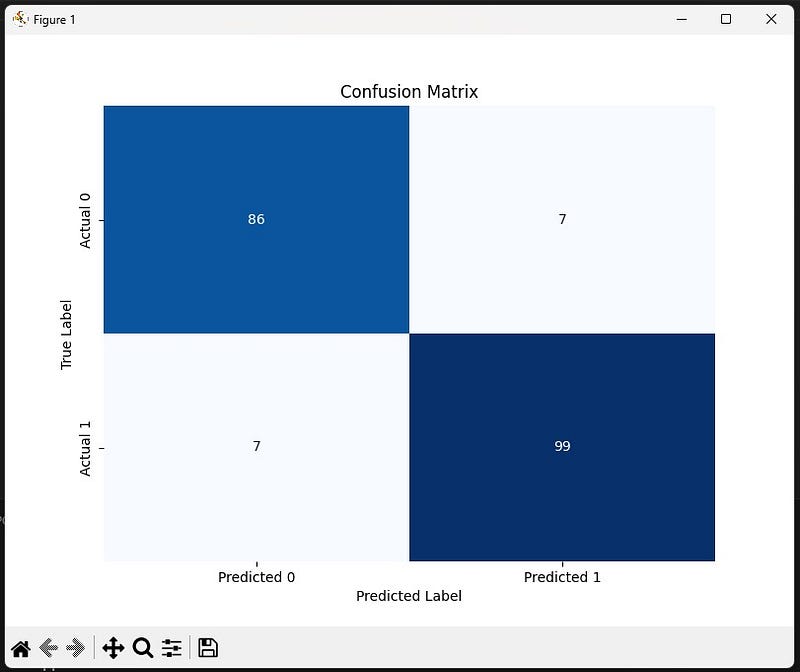
Akurasi sekitar 93%, yang menunjukkan model ini memiliki tingkat keberhasilan yang tinggi dalam memprediksi kelas yang benar. - Matriks Kebingungan (Confusion Matrix):
- True Positives (TP): 99
- True Negatives (TN): 86
- False Positives (FP): 7
- False Negatives (FN): 7
Model cenderung memiliki performa yang baik dalam mengklasifikasikan kelas positif dan negatif, dengan sebagian besar prediksi yang benar.
Laporan Klasifikasi (Classification Report):
- Precision: Precision yang tinggi untuk kelas 0 (0.92) dan kelas 1 (0.93) menunjukkan bahwa model jarang memberikan prediksi positif palsu.
- Recall: Recall yang tinggi untuk kelas 0 (0.92) dan kelas 1 (0.93) menunjukkan bahwa model dapat menemukan sebagian besar instance kelas yang sebenarnya.
- F1-score: F1-score yang tinggi (antara precision dan recall) menunjukkan keseimbangan yang baik antara precision dan recall.
Conclusion
Dengan mempertimbangkan akurasi, presisi, recall, dan nilai f1 yang tinggi, dapat disimpulkan bahwa model Naive Bayes yang diimplementasikan telah memberikan hasil yang sangat baik dalam menangani dataset ini. Tingginya akurasi mengindikasikan bahwa model mampu dengan baik memprediksi kelas yang benar, sedangkan presisi, recall, dan nilai f1 yang tinggi menunjukkan bahwa model tersebut memiliki kemampuan yang kuat dalam mengklasifikasikan instansi dari kedua kelas, baik positif maupun negatif. Hasil ini memberikan keyakinan bahwa model ini dapat diandalkan dalam memprediksi kasus diabetes berdasarkan fitur-fitur yang ada dalam dataset. Selain itu, performa yang konsisten dan handal model dalam mengklasifikasikan instansi dari kedua kelas menambah nilai keandalan model ini dalam berbagai skenario pengujian. Keseluruhan, hasil yang diperoleh dari evaluasi model memberikan dukungan kuat terhadap kemampuan model Naive Bayes dalam menghadapi tantangan klasifikasi pada dataset diabetes ini.